



Next: Comparison of the two
Up: Speedup Measurement
Previous: Analytical speedup
In order to measure speedup, PTidal code (Kaplan, 1997) was
tested using different grids resolutions for the same geometry and
varying the cell size. The test scenery is described in Section
7.2.1. All the below described tests were run with the
computers dedicated to the simulation exclusively.
Table 9.1 displays the speedup employing 4 and 6
processors, over the 4 and 6 DD respectively, working on the
th5, th20 and th80 grids and employing the following ``parallel
computers'':
- A Bull DPX/20 Escala SMP using the
shared memory to pass messages. Latency time 50
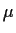 s, bandwidth 230 Mbit/s.(4 Power PC 601 CPUs)
s, bandwidth 230 Mbit/s.(4 Power PC 601 CPUs)
- Same as above but employing sockets message passing. Latency time
1 ms, bandwidth 30 Mbit/s.
- A "parallel virtual machine", formed by a cluster of
workstations running UNIX and connected by a FDDI LAN. Latency time
1 ms, bandwidth 31 Mbit/s.(up to 6 Power PC 601 CPUs)
- A "parallel virtual machine", formed by a cluster of PC's
running UNIX and passing messages through an unswitched Ethernet
LAN. Latency time 1 ms, bandwidth 7 Mbit/s.(up to 10 Intel Pentium
133 MHz CPUs)
Table 9.1:
Speedup in 72 hours of simulation.
| Grid |
Processors |
Workstations |
Escala |
Escala |
| |
|
FDDI |
SMP12.3 |
Sockets |
| th20 |
4 |
2.77 |
2.40 |
2.60 |
| th20 |
6 |
3.60 |
-- |
-- |
| th80 |
4 |
3.00 |
3.00 |
2.80 |
| th80 |
6 |
3.90 |
-- |
-- |
|
Table 9.2 displays the performance attained, measured in
MFLOPS, by the above mentioned parallel computers. Notice the increase
in performance using the th80 grid with respect to the th5 grid
due to the coarser parallelism grain.
The performance improves due to the fact that an increase in the
number of grid points, using the same geometry, time step and number
of processors, is a way to coarse the parallelism grain, thereby
decreasing the communication overhead and attaining a better speedup.
Table 9.2:
MFLOPS attained by the ``parallel virtual machines''.
| Grid |
Processors |
Workstations |
Escala |
Escala |
| |
|
FDDI |
SMP12.3 |
Sockets |
| |
1 |
20.3 |
20.3 |
20.3 |
| th5 |
2 |
32.5 |
-- |
-- |
| th5 |
4 |
48.7 |
-- |
-- |
| th5 |
6 |
60.9 |
-- |
-- |
| th20 |
2 |
36.5 |
-- |
-- |
| th20 |
4 |
56.2 |
48.7 |
52.8 |
| th20 |
6 |
73.1 |
-- |
-- |
| th80 |
2 |
37.6 |
-- |
-- |
| th80 |
4 |
60.9 |
60.9 |
56.8 |
| th80 |
6 |
79.2 |
-- |
-- |
|
Next: Comparison of the two
Up: Speedup Measurement
Previous: Analytical speedup
Elias Kaplan M.Sc.
1998-07-22